作者:Tina19Or多多 | 来源:互联网 | 2023-08-20 19:51
篇首语:本文由编程笔记#小编为大家整理,主要介绍了玩转Rabbitmq系列01:一文带你敲响Rabbitmq的大门相关的知识,希望对你有一定的参考价值。

🏠个人主页:啊陈晓
🎉学习方向:java后端开发
🎁我的上一篇文章:手把手带你搭建第一个SpringCloud项目(二)
💕如果我的文章对你有帮助,点赞、收藏、留言都是对我最大的动力

【玩转Rabbitmq系列】文章直通车~
【玩转Rabbitmq系列】01:一文带你敲响Rabbitmq的大门
【玩转Rabbitmq系列】02:Rabbitmq保姆级安装教程与基本消息模型实战
未完待续.........
现在让我们正式开启进入今天的正文
文章目录
-
前言
-
一、什么是Rabbitmq
-
二、为什么我们要使用消息中间件
-
三、选择Rabbitmq的原因
-
四、Rabbitmq的四大核心概念
-
五、Rabbitmq的六大消息模型
-
总结
前言
在学习任何技术之前,我们都必须要先了解这门技术的用处、选择这门技术的原因、能给自己带来什么样的帮助,这样学习起来才会更有动力。而今天,在我们正式开始学习Rabbitmq这门技术之前,我们不妨先来了解一下什么是Rabbitmq,我们又为什么选择它。
一、什么是Rabbitmq
Rabbitmq是一个在AMQP(高级消息队列协议)基础上完成的,可复用的企业消息系统,用于软件之间的通信,是当前最主流的消息中间件之一。

说到这里,大家可能又会问了,Rabbitmq的本质是一个消息中间件,那什么又是消息中间件呢?
消息中间件就是利用高效可靠的消息传递机制进行异步的数据传输,并基于数据通信进行分布式系统的集成。通过提供消息队列模型和消息传递机制,可以在分布式环境下扩展进程间的通信。
人话:应用之间的一个组件,应用双方通过这个消息组件进行通信。
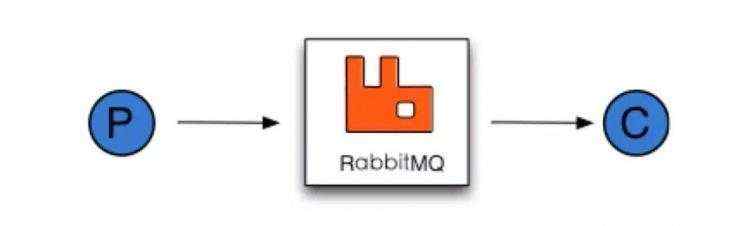
就如下图所示,P、C之间中间是使用Rabbitmq来实现消息的传递、实现通信。
二、为什么我们要使用消息中间件
在现实的场景和应用中,我们使用消息中间件,主要是为了解决下面的这三个问题:
1.应用解耦
当今微服务架构盛行,一个应用从传统的应用巨石被拆分成多个微服务,在这个由众多系统构成的应用中,如果采用传统的消息传递方式,则会导致系统之间高度耦合,严重影响系统的开发和维护效率。
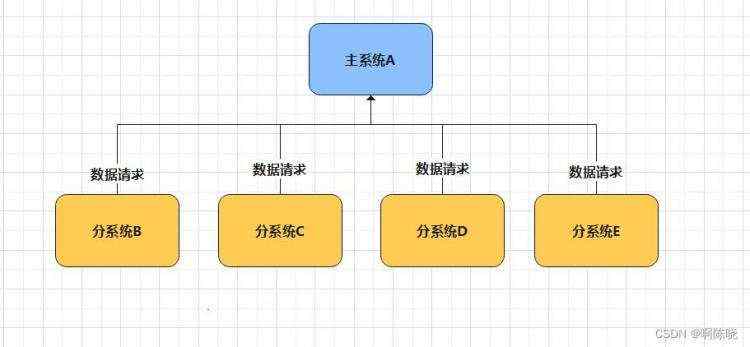
举个例子:假设A有一份应用的核心数据,B、C、D、E在需要数据时都必须对A发起请求,如果系统的数量不多,那A可以通过接口直接将数据传递给各个系统。但是如果系统的数量进一步增加,A还要一个个将系统传递给几十甚至成百上千个系统吗?如果其中系统中有一个瘫痪、抛出异常,因为高度耦合的关系我们是不是也要去检查A中的业务逻辑?这在实际开发中将严重影响到我们的开发效率和系统性能。
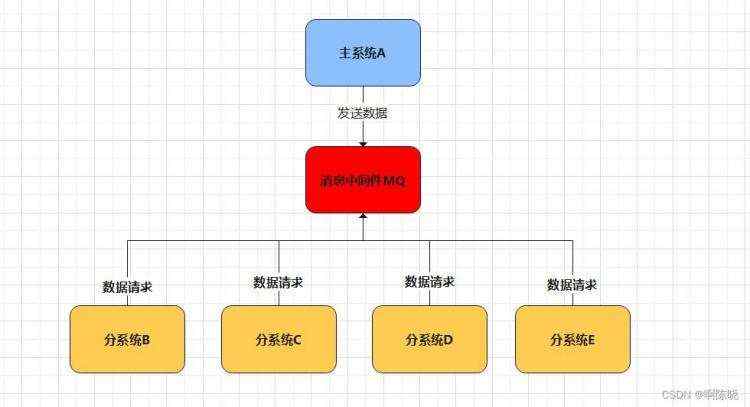
为了解决这个问题,我们便引入消息中间件MQ
如下图所示,我们在A和其他系统中引入消息中间件MQ,A将最核心的数据发送给消息中间件。其他系统通过MQ来实现对核心数据的访问,即使系统数量发生变动也不会影响到A的业务逻辑,实现了系统的解耦。
2.流量消峰
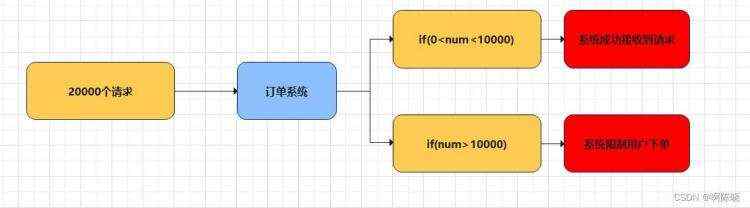
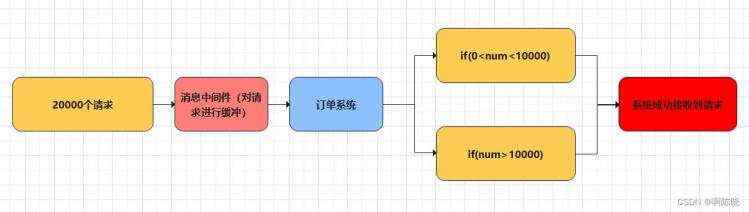
还是举个例子:如果一个订单系统在一段时间内最高只能处理一万笔订单,在正常时间段处理各种下单业务绰绰有余。但是在高峰期的时候,订单的数量来到了两万笔,此时系统便处理不了,只能去限制超过一万订单的数量不能下单。这会严重影响到系统的可用性,降低用户体验。
我们也可以通过引入MQ的方式解决上述问题
如下图所示,我们加入消息中间件对20000个请求进行缓冲,把订单分散成一段时间进行处理。这样有一些用户可能会等待一小段时间,但是这远比系统不可用的体验感要好得多。
3.异步处理
在传统的业务逻辑中,业务之间的调用通常是顺序性,在这种情况下,即使业务之间的调用所消耗的时间很短,但是因为业务太多也会导致整个业务逻辑时间执行下来花费太多的时间。
举个例子:我们在系统中发起一个请求时时,需要经历如下图所示的业务链:

因为业务链是顺序执行的,所以执行完成共花费20ms.但是在一些复杂的业务系统中,所需要付出的代价就远远不止20ms了,因此我们必须找出更好的方案来减少整个业务完成的时间。
对于上述的问题,我们还是可以通过引入消息中间件来解决。
如下图所示,我们以业务2、业务3为例,让他们先将消息发送到消息中间件中,后业务2、业务3下的其他业务再通过消息中间件来获取对应的消息,让业务3不必等到业务2完全执行完再执行,通过消息中间件实现了业务之间的异步处理。这便极大程度上缩短了业务的执行时间,提高了系统的可用性。

三、选择Rabbitmq的原因
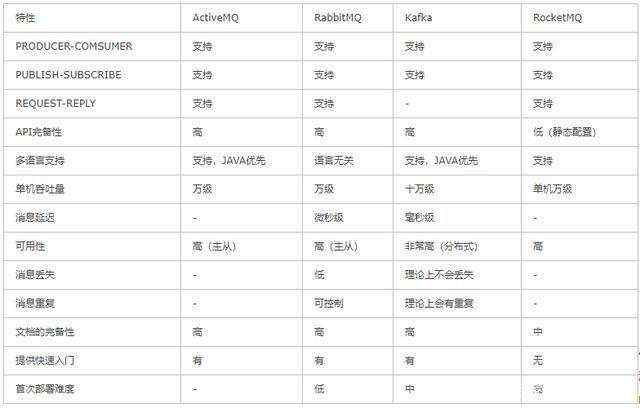
在现在的市场上,有很多消息中间件的技术,为什么我们选择了Rabbitmq?
常见的消息中间件
那是因为Rabbitmq具有下面的特性:
- 遵循AMQP协议
- 可靠性高,消息持久化能够能保证消息的稳定性
- 集群部署简单,应用Erlang使得RabbitMQ集群部署变的超级简单
- WEB管理和监控,为后期运维提供很大的便利
- 功能丰富,支持消息持久化、支持消息确认机制、灵活的任务分发机
- 大量成功的应用案例,例如阿里、网易等互联网巨头都有使用。
基于以上的特性,对于市面上绝大多数中小型公司中数据量没有很大的项目来说。功能完备的Rabbitmq是一个非常好的选择。
四、Rabbitmq的四大核心概念
简单点来说,Rabbitmq其实就像一个快递站点,不过他所传递的是消息而并非快递,接下来我们就以快递站点为例子引出Rabbitmq的四大核心概念。
在Rabbitmq中,有着以下四大核心概念:
-
生产者(producer)
生产者是产生数据发送消息的程序
交换机是 RabbitMQ 非常重要的一个部件,一方面它接收来自生产者的消息,另一方面它将消息推送到队列中。交换机必须确切知道如何处理它接收到的消息,是将这些消息推送到特定队列还是推送到多个队列,亦或者是把消息丢弃,这个得有交换机类型决定
队列是 RabbitMQ 内部使用的一种数据结构,尽管消息流经 RabbitMQ 和应用程序,但它们只能存储在队列中。队列仅受主机的内存和磁盘限制的约束,本质上是一个大的消息缓冲区。许多生产者可以将消息发送到一个队列,许多消费者可以尝试从一个队列接收数据。这就是我们使用队列的方式
消费与接收具有相似的含义。消费者大多时候是一个等待接收消息的程序。请注意生产者,消费 者和消息中间件很多时候并不在同一机器上。同一个应用程序既可以是生产者又是可以是消费者。
简单来说,拿快递站点来比喻,生产者即是商家,由商家(生产者)发出快递(信息),然后由快递站(交换机)接收,快递站(交换机)必须知道快递(信息)是发往那条运行通道(队列),最终快递(消息)通过运行通道(队列)到达用户(消费者)手中。
五、Rabbitmq的六大消息模型
1、基本消息模型

即一个消费端(C)接收一个生产端(P)发送在消息队列(图中红色部分)中的信息。
2 、work消息模型
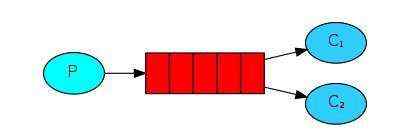
即两个消费端(C1)、(C2)共同消费一个生产端(P)发送在同一个消息队列(图中红色部分)中的信息,但是一个消息只能被一个消费者获取,C1、C2之间是竞争关系。
3、Publish/subscribe模式
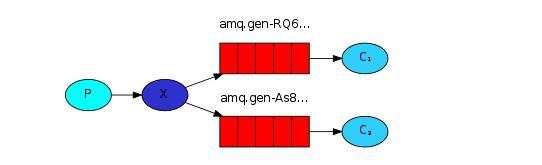
即生产者(P)将消息发送到交换机(X)中,此处的交换机是Fanout(广播类型),交换机将消息广播发送给两个消息队列(图中两个红色部分),然后消费者C1、C2再分别从对应的队列中获取消息。
4、Routing 路由模型
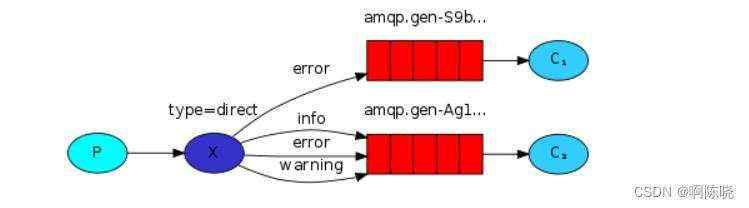
即生产者(P)将带着routing-key的消息发送到交换机(X)中,此处的交换机是direct(直接类型),交换机将消息中routing-key与队列中所带的routing-key进行匹配,即图中的error、info、warning,匹配成功则将消息发送给对应的消息队列(图中两个红色部分),然后消费者C1、C2再分别从对应的队列中获取消息。
5、Topics 通配符模式
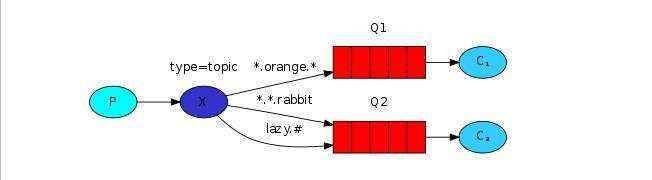
即生产者(P)将带着routing-key的消息发送到交换机(X)中,此处的交换机是topic(主题模式),交换机将消息中routing-key与队列中所带的通配符进行匹配,即图中的*.orange.*、*.*.rabbit、lazy.#,匹配成功则将消息发送给对应的消息队列(图中两个红色部分),然后消费者C1、C2再分别从对应的队列中获取消息。
通配符规则:
#:匹配0个或多个词
*:匹配1个词
例子:
*.orange.*:成功:a.orange.b、ok.orange.ok1 失败:a.orange.b.c 、orange.b
azy.#:成功:azy、azy.a、azy.b.c 失败:a.azy
6、RPC
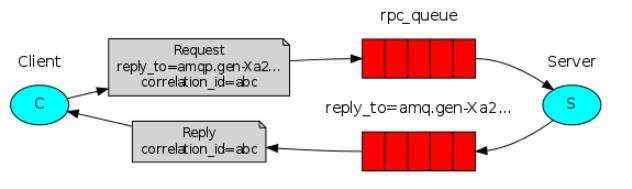
- 即客户端(P)启动时,会创建一个匿名独享的回调队列(amqp.gen-Xa2)
- 客户端(P)为RPC请求设置2个属性:replyTo(用于设置回调队列名字);correlationId(用于标记request)
- 请求被发送到rpc_queue队列中
- RPC服务器端(S)监听rpc_queue队列中的请求,当请求到来时,RPC服务器端(S)会处理并且把带有结果的消息发送给客户端(P)。接收的队列就是replyTo设定的回调队列。
- 客户端(P)监听回调队列(amqp.gen-Xa2),当有消息时,检查correlationId属性,如果与request中匹配,即取出结果
总结
看到这里,相信你已经对Rabbitmq有了一个初步的了解,也许你还存在一些没有特别理解的地方,没关系,在接下的系列文章里,我将从简单到复杂,从配置到实现一步步带你深入Rabiitmq的世界!!
至此,我们今天的教程就到此结束啦~
感谢您的阅读,希望我的文章能给你带来帮助!!!








 京公网安备 11010802041100号
京公网安备 11010802041100号